

데이터베이스에서 데이터를 식별하기 위해 PK를 통해 데이터를 식별하게 된다. PK를 숫자로 지정해 둔 경우, 데이터베이스에 대한 공격에 취약한 경우가 있기 때문에 url에 PK값을 노출하는 방식은 좋지 않다고 한다.
이를 보완하기 위해 UUID를 사용하는 방법이 있다!
UUID는 32개의 문자와 4개의 하이픈으로 구성된 문자열이며 8-4-4-4-12 개의 문자열로 이루어져 있으며 5가지 버전을 가지고 있다.
UUID(Universally Unique Identifier)의 정의 및 구조
1. UUID의 정의
💡 UUID(Universally Unique Identifier)란?
범용 고유 식발자를 의미하며 중복이 되지 않는 유일한 값을 구성하고자 할 때 주로 사용되는 고유 식별자이다.
주로 세션 식별자, 쿠키 값, 무작위 데이터베이스 키 등에 사용된다.
2. UUID 구조
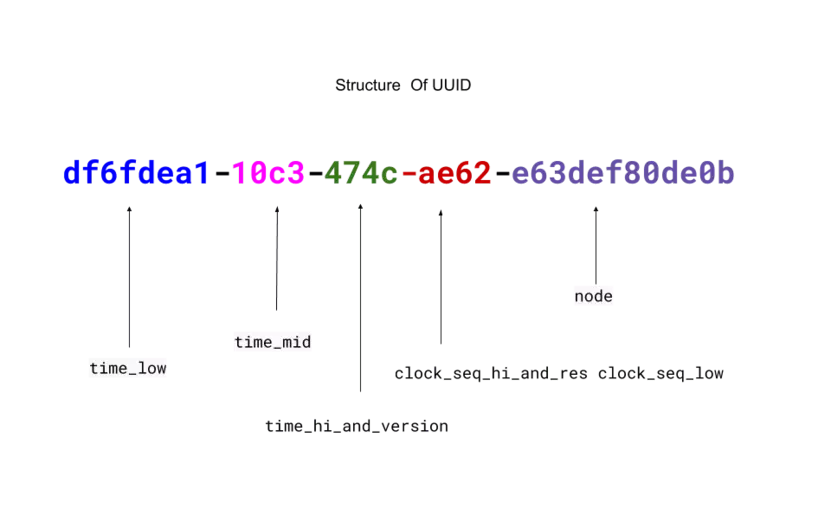
💡 UUID는 16바이트(128비트) 형태의 구조를 가짐.
하나의 UUID 길이는 36자리이며 4개의 하이픈과 32개의 16진수 문자열로 구성되어있음 !
| 구조 | 길이 | 내용 |
| time_low | 4 / 8 (8자리) | 시간의 low 32비트를 부여하는 정수 |
| time_mid | 2 / 4 (4자리) | 시간의 middle 16비트를 부여하는 정수 |
| time_hi_and_version | 2 / 4 (4자리) | 최상위 비트에서 4비트 version, 그리고 시간의 high 12비트 |
| clock_seq_hi_and_res_clock_seq_low | 2 / 4 (4자리) | 최상위 비트에서 1-3비트는 UUID의 레이아웃형식, 그리고 13-15비트 클럭 시퀀스 |
| node | 6 / 12 (12자리) | 48비트 노드 id |
🤔 중복된 UUID가 생길 가능성이 있을까?
랜덤된 값을 생성한다는 UUID는 이론상으로는 중복값이 생성될 가능성이 존재한다. 하지만 UUID의 총 생성 가능 개수는 340,282,366,920,938,463,463,374,607,431,768,211,456개로 중복된 값이 생길 확률을 계산해보면 초당 10억개의 UUID를 100년동안 생성했을 시 중복된 값이 생길 확률이 50%이기 때문에... 중복된 값은 걱정하지 않아도 될 것 같다.ㅎㅎ
3. UUID의 버전
| 버전 | 설명 | 특징 |
| UUID Version1 | 현재 시간 + 랜덤한 MAC 주소 | 유일성 보장됨 보안에 취약 |
| UUID Version2 | 버전 1과 유사하지만, 시퀀스 번호 대신 POSIX UID(사용자 ID) 사용 | 현재는 거의 사용되지 않는다 |
| UUID Version3 | 해시 함수인 MD5 해시를 기반으로 이름과 네임스페이스에 대한 조합 | 암호화 해시 함수를 사용하여 생산하므로 보안성 높다 이름과 네임스페이스가 같다면 같은 UUID가 생성 |
| UUID Version4 | 랜덤한 값 | 보안성이 높고 생성속도가 빠르다 |
| UUID Version5 | 버전 3과 유사하지만, SHA-1 해시 사용 | 보안에 취약하다는 단점.. |
아래에서는 자주 사용되는 Version1과 Version4에 대해서만 글을 작성해볼 예정이다.!
UUID version 1
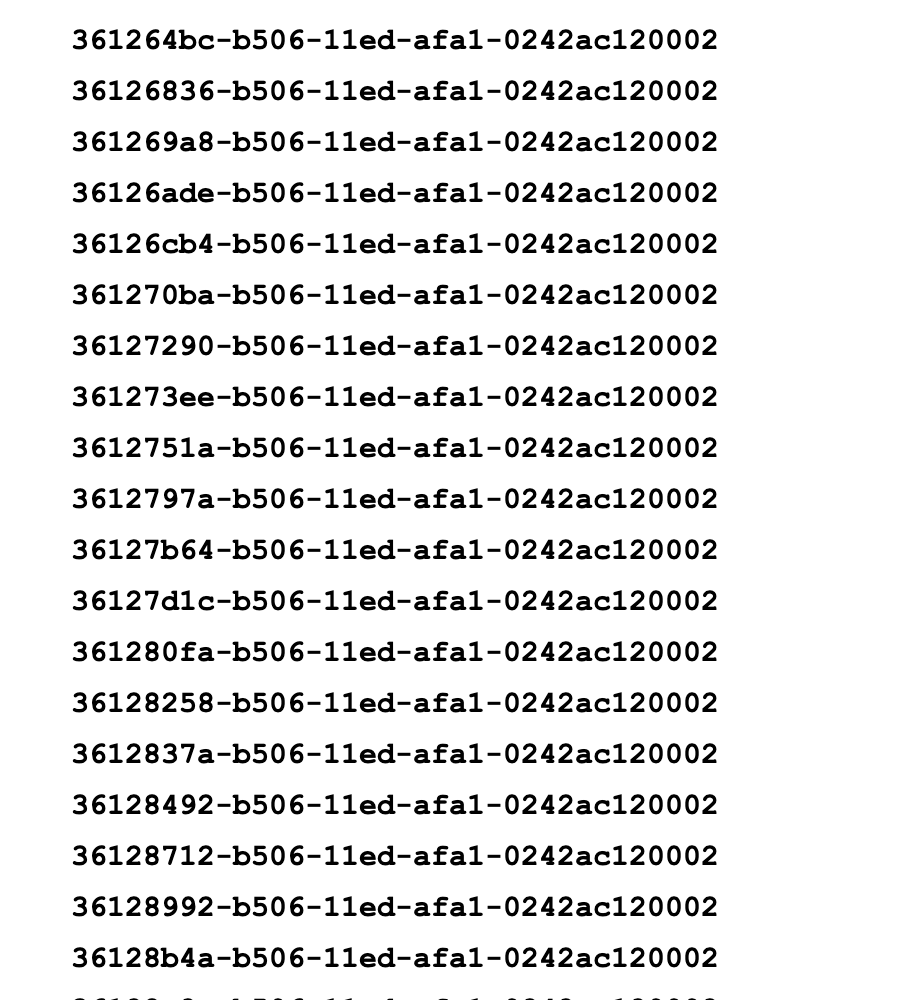
💡해당 버전은 MAC 주소와 타임스탬프(현재 시간)을 기반으로 UUID를 생성해준다.
동시간대에 생성했을 때 앞의 8자리 문자열만 바뀌는 것을 확인할 수 있음. 각자 다른 컴퓨터가 같은 시간대에 UUID를 생성할 경우 MAC주소가 다르기 때문에 앞의 8자리 문자외 다른 문자 또한 다른 UUID가 생성될 것이다!
⚠️ 단점 : 유일성이 보장되지만, 보안에 취약함
import java.util.UUID;
/**
* [MAC Address] MAC 주소 대신에 임의의 48비트 숫자를 생성합니다.(보안 우려로 이를 대체합니다)
* @return
*/
private static long get64LeastSignificantBitsForVersion1() {
Random random = new Random();
long random63BitLong = random.nextLong() & 0x3FFFFFFFFFFFFFFFL;
long variant3BitFlag = 0x8000000000000000L;
return random63BitLong | variant3BitFlag;
}
/*
* [TimeStamp] 타임스템프를 이용하여 64개의 최상위 비트를 생성합니다.
*/
private static long get64MostSignificantBitsForVersion1() {
final long currentTimeMillis = System.currentTimeMillis();
final long time_low = (currentTimeMillis & 0x0000_0000_FFFF_FFFFL) << 32;
final long time_mid = ((currentTimeMillis >> 32) & 0xFFFF) << 16;
final long version = 1 << 12;
final long time_hi = ((currentTimeMillis >> 48) & 0x0FFF);
return time_low | time_mid | version | time_hi;
}
/**
* UUID v1을 생성하여 반환합니다.(MAC Address, TimeStamp 조합)
*
* @return
*/
public static UUID generateType1UUID() {
long most64SigBits = get64MostSignificantBitsForVersion1();
long least64SigBits = get64LeastSignificantBitsForVersion1();
return new UUID(most64SigBits, least64SigBits); // 62dd98f0-bd8e-11ed-93ab-325096b39f47
}
📖 MAC Address (Media Access Control) 이란?
네트워크 인터페이스를 식별하기 위한 고유한 주소. 전 세계에서 유일하며, 일반적으로 12자리 16진수로 나타낸다!
UUID version 4

💡 보안 난수 생성기를 이용해 모두 다른 ID가 생성된다. 중간에 숫자 4가 고정적으로 박혀있는 것을 볼 수 있는데 이는 버전을 나타내기 위한 표시임.
🌟 보안성이 높고 생성 속도가 빠르다는 장점을 가지고 있어 대중적으로 많이 사용되는 UUID 버전이다!
import java.util.UUID;
// 버전 4 UUID 생성하기
UUID uuid4 = UUID.randomUUID();
System.out.println("Version 4 UUID: " + uuid4); // Version 4 UUID: c48b2aef-9d79-44fe-bd97-46fd31361069
4. 데이터베이스에 UUID를 도입했을 때 장점
1. 보안
유저 삭제, 게시글 삭제 등의 API를 호출할 때 데이터베이스에 존재하는 PK값을 가지고 클라이언트가 API서버로 호출을 하게 된다. 이때 PK가 숫자로 되어 있을 경우 다른 유저나 게시글의 PK를 유추해 접근을 시도 할 수 있다.
하지만 UUID를 사용했을 경우 모든 PK는 유추가 불가능 하기 때문에 보안상에서 안전하다.
2. 연관관계의 데이터를 입력할 때
연관관계의 데이터를 같이 입력하게 된다면, 데이터 베이스에 저장된 PK의 값을 가지고 FK를 지정해서 입력해 줘야한다. ORM을 쓸경우 ORM이 알아서 맵핑해 주지만, ORM을 쓰지 못할 경우엔 입력된 데이터를 가지고 FK를 지정 해 줘야하는데, UUID를 사용할 경우, 서버에서 UUID를 생성 후 PK와 FK를 같이 지정해 입력 할 수 있다.
3. 데이터베이스의 데이터를 합칠 때
흩어져있는 데이터를 합칠때 데이터의 중복이나 충돌 없이 안전하게 데이터를 병합할수 있다.
5. 데이터베이스에 UUID를 도입했을 때 단점
1. 운영 비용의 증가
UUID는 32자리 문자로 이루어져 있으며 몇번을 생성하는 똑같다. BIGINT PK와 비교해보면 더 많은 디스크를 차지하게 되고 인덱스의 크기가 커져 메모리 또한 많이 차지하게 된다.
2. 정렬이 힘들다
UUID는 랜덤한 값이다 이를 정렬한다는것은 매우 어려워 별도의 인덱스나 생성시간에 따른 정렬을 따로 구현해야 한다.
3. 몇몇 데이터베이스는 기본 기능으로 제공하지 않는다
현재 가장 많이 사용하고 있는 데이터베이스인 MySQL의 경우, UUID의 자동생성을 기본적으로 제공하지 않는다. MySQL에서 사용할 경우, 함수를 직접 설정해서 UUID를 생성해야 한다.
PostgreSQL은 UUID의 자동생성을 지원하며, UUID를 사용할 경우 PostgreSQL을 사용해 보자
6. import java.util.UUID 메소드 종류
| 메소드 | 설명 |
| static UUID randomUUID() | 무작위 UUID 생성 |
| static UUID fromString(String uuid) | static UUID fromString(String uuid) |
| long getLeastSignificantBits() | UUID의 가장 낮은 64비트 반환 |
| long getMostSignificantBits() | UUID의 가장 높은 64비트 반환 |
| int compareTo(UUID val) | UUID와 주어진 UUID 비교 |
| String toString() | UUID를 문자열로 반환 |
| boolean equals(Object obj) | UUID와 주어진 객체가 같은지 여부 반환 |
'Backend > Java' 카테고리의 다른 글
| [Java] trim(), strip() 차이점 / java 문자열 앞뒤 공백 제거 (0) | 2024.02.28 |
|---|---|
| [Lombok] Constructor Annotation 정리 (0) | 2024.01.05 |
| [Lombok] Lombok Annotation 정리 (4) | 2024.01.02 |
| [Java] Java SE 17 설치 및 환경설정 (JDK 17, Windows 11) (0) | 2023.12.20 |
